🪄 ControlNet modalities
ControlNet provides a greater degree of control over text-to-image generation by conditioning the model on additional inputs such as edge maps, depth maps, segmentation maps, and keypoints for pose detection.
With Scenario, you can use those modalities: canny, depth, illusion, lineart, lines, normal-map, pose, scribble, and seg. Find below a quick description and examples of those modalities.
| Modality | Description | Control image | Generated Image |
|---|---|---|---|
| canny | A monochrome image with white edges on a black background. |  |  |
| depth | A grayscale image with black representing deep areas and white representing shallow areas. |  |  |
| illusion | A range of grey shades from white to black. Can be used for ControlNet illusion |  |  |
| lineart | A monochrome image with white soft edges on a black background. |  |  |
| lines | A monochrome image composed only of white straight lines on a black background. |  |  |
| normal-map | A normal mapped image. |  |  |
| pose | A OpenPose bone image. | 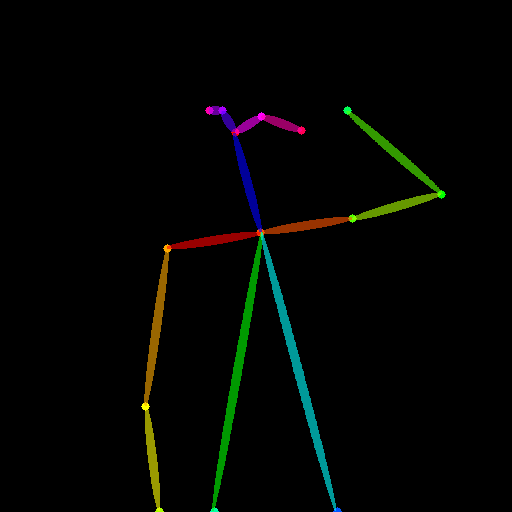 |  |
| scribble | A hand-drawn monochrome image with white outlines on a black background. |  |  |
| seg | An ADE20K's segmentation protocol image. |  |  |
Sources: https://huggingface.co/lllyasviel/sd-controlnet-canny
Updated 19 days ago